Efinix TinyML Accelerator加速方案整理
3/19/25...About 1 min
Efinix TinyML Accelerator加速方案整理
本文整理了在官方 TinyML repo中的tools\tinyml_generator.py用到的一些常見加速方案
卷積並行計算 Convolution Parallelism
modify_in_out_parallel_param()
多維卷積運算需要大量乘法計算,以2D圖像為例:
- 參數
CONV_DEPTHW_STD_IN_PARALLEL,CONV_DEPTHW_STD_OUT_PARALLEL可分別調整STANDARD模式的IN/OUT的並行數 - 因為需要獨立的adder, multipier,DSP block, RAM等資源消耗會顯著增加
- 最大的並行數設定不可超過AXI_DW/8 (Ti60設定AXI_DW為128)
剪枝/降維 Pruning/Dimensionality Reduction
- Fully Connected(FC)設定為LITE模式時:FC_MAX_IN_NODE, FC_MAX_OUT_NODE被設定為640
- 影響輸入特徵數量及輸出準確度
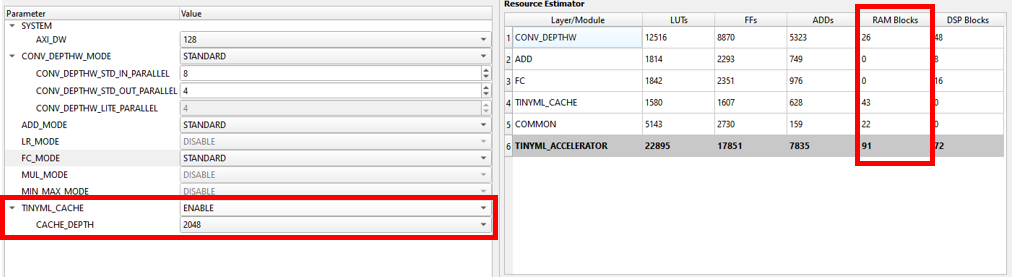
快取 CACHE
modify_cache_param()
將model常用的input feature, weight等直接放在FPGA BRAM(Block RAM),減少從NVM (ex. flash)搬運的時間
- 只對STANDARD模式有效
CACHE_DEPTH不夠時會造成載入模型時當機 <- (檔案不完整?)- Ti60有256個BRAM,可使用resource estimator確認預估消耗的數量
模型轉換 Conversion
parse_model(), dump_model()
將.tflite模型預先轉換為.c hex array,以供FPGA在底層直接使用(aka. 減少開機載入時間)