自動編碼器 Autoencoder:理論篇
自動編碼器 Autoencoder:理論篇
沒有畫作的藝術展
請想像有一個藝術展覽,但完全沒有任何一幅畫作展出,只有一個畫家小明和一個超大牆壁,而牆壁包含X軸與Y軸,且布滿了很多小點(圖1)。
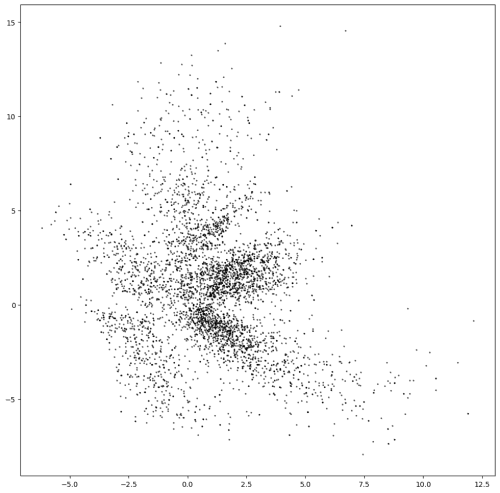
其中的特別之處在於,這面牆壁並不單純。上面的每一個小點代表一幅畫作,是由工作人員所整理的XY分布圖。而小明也非等閒之輩,他可以記下所有XY座標所代表的畫作,並現場繪製出來。每當客人要看畫作時,小明就在牆壁上選一個點,並且記下(X,Y)的資訊。依照(X,Y)資料,小明可以繪製出一個對應的畫作,如圖2。
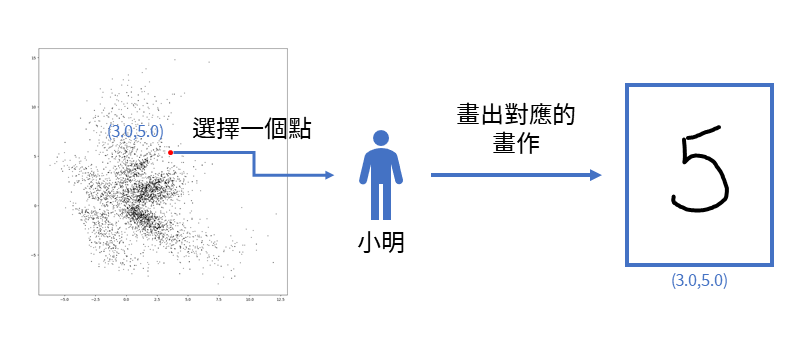
自動編碼器
以上的故事是來自D. Foster的《Generative deep learning》這本書中的經典案例[1],而這個藝術展就是一個自動編碼器(Autoencoder),包含了:
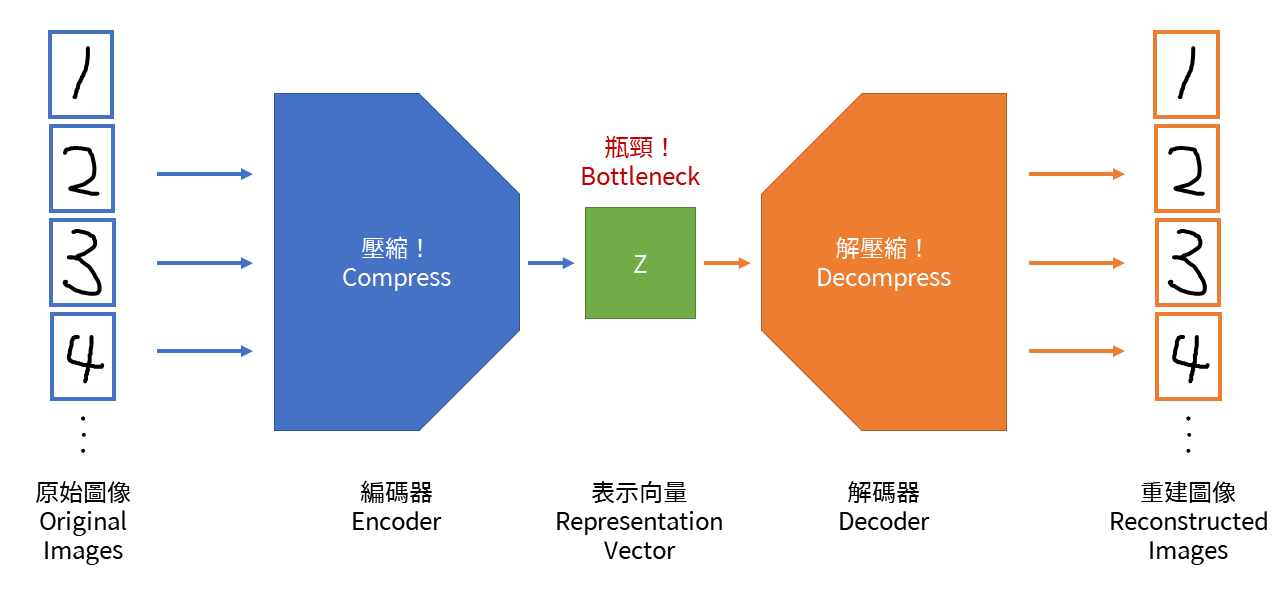
- 編碼器(Encoder):負責將圖像壓縮成低維的資料。(工作人員)
- 表徵向量(Representation Vector):一個用於分析的低維資料,是一種隱含空間(Latent Space)。依照上面的範例來說,是一個表示畫作與(X,Y)之對應關係的2維資料。(超大牆壁)
- 解碼器(Decoder):負責從低維的資料轉換回圖像。(小明的工作)
為何要將所有圖像的對應關係轉成低維的資料,而又轉回圖像呢?這是為了要找出圖像的特徵,而進行降維。也就是說,編碼器將畫作不必要的成分去除掉,只留下重要的特徵,這時分析畫作就變得十分容易,而這個動作稱為瓶頸(Bottleneck)。分析完畢後,機器就可以得知其中的規律,此時就可以透過解碼器將畫作重新畫出來。(圖3)
而因為這個結構可以自動地將圖像編碼,找到其中的特徵,並產生表徵向量,故得其名。從這個流程來看,我們可以發現自動編碼器是一個非監督式學習(Unsupervised learning)的機器學習模型(Model)。
用途
自動編碼器可用於以下任務:
- 特徵辨識:利用瓶頸的特性,自動編碼器能夠高效率地抓到圖片的特徵,進而分辨圖像。
- 圖片降噪:自動編碼器可提取圖像中的重要部分,以此把噪點去除。這同樣也是應用了瓶頸特性。
- 生成資料:自動編碼器可嘗試生成與輸入的資料相似的新資料,如圖片、文字或音訊等。
損失函數(Loss Function)
自動編碼器的常用損失函數有以下兩種,用來評估原始圖像(Original Images)和重建圖像(Reconstructed Images)之間的差異:
- 均方根誤差(Root Mean Squared Error, RMSE)
- 二元交叉熵(Binary Cross-entropy)
其中二元交叉熵對於極端的情況會施加更重的懲罰,使表示向量(潛在空間)分布往中間集中,這將導致生成的圖像不太生動。但實際的運用方式須依照不同的任務作不同的選擇,而非一定得用兩者其中一種。[1:1]
延伸變體
- 降噪自動編碼器(Denoise Autoencoder, DAE):以含有雜訊的圖集做訓練,並找出其中的隱含特徵,捨棄不重要的雜訊。[2]
- 自動上色自動編碼器:以灰階圖像訓練,並要求輸出產生彩色圖片。這可使自動編碼器找出隱藏結構(利用瓶頸特性),並將原始灰階圖像上色。[2:1]
- 變分自動編碼器(Variational Autoencoder, VAE):利用變分推斷,使其具備可解譯的潛在編碼來產生連續的潛在編碼映射。[2:2]
- 稀疏自動編碼器(Sparse Autoencoder, SAE):以稀疏性限制來達成瓶頸的效果。