變分自動編碼器 Variational Autoencoder:理論篇
簡介
變分自動編碼器(Variational Autoencoder, VAE)的概念是由 Diederik P. Kingma 與 Max Welling 在論文《Auto-Encoding Variational Bayes》所提出,其利用貝式定理進行 變分推斷 ,之中還運用了 重參數化 (reparameterization)來預估ELBO,使其可用常見的優化器來最佳化。其結構和自動編碼器(Autoencoder, AE)類似,一樣以編碼器和解碼器組成,並且在學習潛在向量 z 的同時,還要做到重構(reconstruct)資料。不同的地方是:相較於AE,VAE會 嘗試從一個可編碼的連續潛在空間去對應輸入的分配建模 。且 VAE 把解碼器當成生成模型來使用,這使其具備 生成性 (generative)。
VAE 的目標
生成模型的目標是運用神經網路來近似輸入資料(圖像等)的真實分配:
x∼Pθ(x)
其中θ是在訓練過程中所決定的參數。(如:找到可繪製各種臉部的分配)
要做到一定程度的推論,需要找到Pθ(x,z),也就是輸入x與潛在變數z之間的聯合分配。其中潛在變數z是由輸入的特徵編碼而來(如:臉部的五官、表情等)。而Pθ(x,z)可由邊際分配求出,如下式:
Pθ(x)=∫Pθ(x,z)dz
簡單來說,我們希望可以建構一個可描述輸入資料的分配(如:眼睛大、鼻子挺、嘴巴小的男性臉部)。而其中的一大難處在於,式 2 是 難解的 (intractable),因為它不具備任何分析形式或有效的估計量。原因如下:
將式 2 以貝式定理的乘法法則改寫成如下式時:
Pθ(x)=∫Pθ(x∣z)P(z)dz
其中Pθ(x∣z)是z的事前機率,也就是沒有對任何觀察值加上條件。我們可以有兩種假設:
- 假設z是離散,且Pθ(x)是高斯分配,則Pθ(x)是一個高斯混合。
- 假設z為連續,則Pθ(x∣z)是無限高斯混合。
如果沒有一個合適的損失函數去近似Pθ(x∣z),則會直接忽略z,並得到Pθ(x∣z)=Pθ(x)。這樣一來,我們無從得知Pθ(x)的估計值。
將式 2 改寫成如下式時:
Pθ(x)=∫Pθ(z∣x)P(x)dz
此式中的Pθ(z∣x)同樣不可解。
為了可以估計Pθ(z∣x),我們可以使用變分推斷(variational inference)去找到一個可解的分配。也就是說, VAE 的目標是近似Pθ(z∣x) 。
變分推斷(Variational Inference)
VAE 採用了變分推斷模型作為編碼器來近似Pθ(z∣x),如下式:
Qϕ(z∣x)≈Pθ(z∣x)
Qϕ(z∣x)是Pθ(z∣x)的估計值,透過最佳化參數ϕ,Qϕ(z∣x)就可利用深度神經網路來求近似使其可解。我們可以使用 多變量高斯 來挑選Qϕ(z∣x),如下式:
Qϕ(z∣x)≈N(z;μ(x),diag(σ(x)))
其中的平均數μ(x)與標準差σ(x)可由編碼器使用輸入的資料來計算,且其中的對角矩陣表示z的元素彼此獨立。
損失函數(Loss Fuction)推導
我們可以使用 KL 散度 (Kullback-Leibler divergence)來計算Qϕ(z∣x)Pθ(z∣x)之間的誤差(可視作某種距離)。(KL 散度簡介見補充1.)如下式:
DKL(Qϕ(z∣x)∣∣Pθ(z∣x))=Ez∼Q[logQϕ(z∣x)−logPθ(z∣x)]
使用貝式定理
Pθ(z∣x)=Pθ(x)Pθ(x∣z)Pθ(z)
來展開式 7,如下式:
DKL(Qϕ(z∣x)∣∣Pθ(z∣x))Ez∼Q[logQϕ(z∣x)=−logPθ(x∣z)−logPθ(x)]+logPθ(x)
由於z∼Q並不相依,上式中的logPθ(x)可視作是一個微分常量,故可重新整理後可得如下式:
logPθ(x)−DKL(Qϕ(z∣x)∣∣Pθ(z∣x))Ez∼Q[logPθ(z∣x)]−DKL=(Qϕ(z∣x)∣∣Pθ(x))
式 10 解釋:
總結以上,可得 VAE 的損失函數LVAE為:
LVAE=LR+LKL
重參數化(Reparameterization)
VAE 中為解決後向傳播時梯度無法經過隨機 sampling 的問題,將 sampling 過程重參數化,並視其為輸入的一部份,修改過程如下所示:
[Sample=μ+σ]⇒[Sample=μ+∈σ]
其中∈為重參數取樣,並整併至標準差σ後,再與平均數μ相加。
這樣一來,VAE 將可使用常用的 Optimizer(如:Adam)來最佳化。
VAE 架構總結
如圖1所示,左方為編碼器,其輸出不再直接輸出z,而是輸入資料x的平均數μx與標準差σx。並同時從輸入資料x採樣得到∈後(∈為高斯分佈),進行如下式之運算,計算出潛在空間z:
z=μx+σx∘∈
而圖1右方為解碼器,其在潛在空間z採樣並還原資料(如:圖像等)。
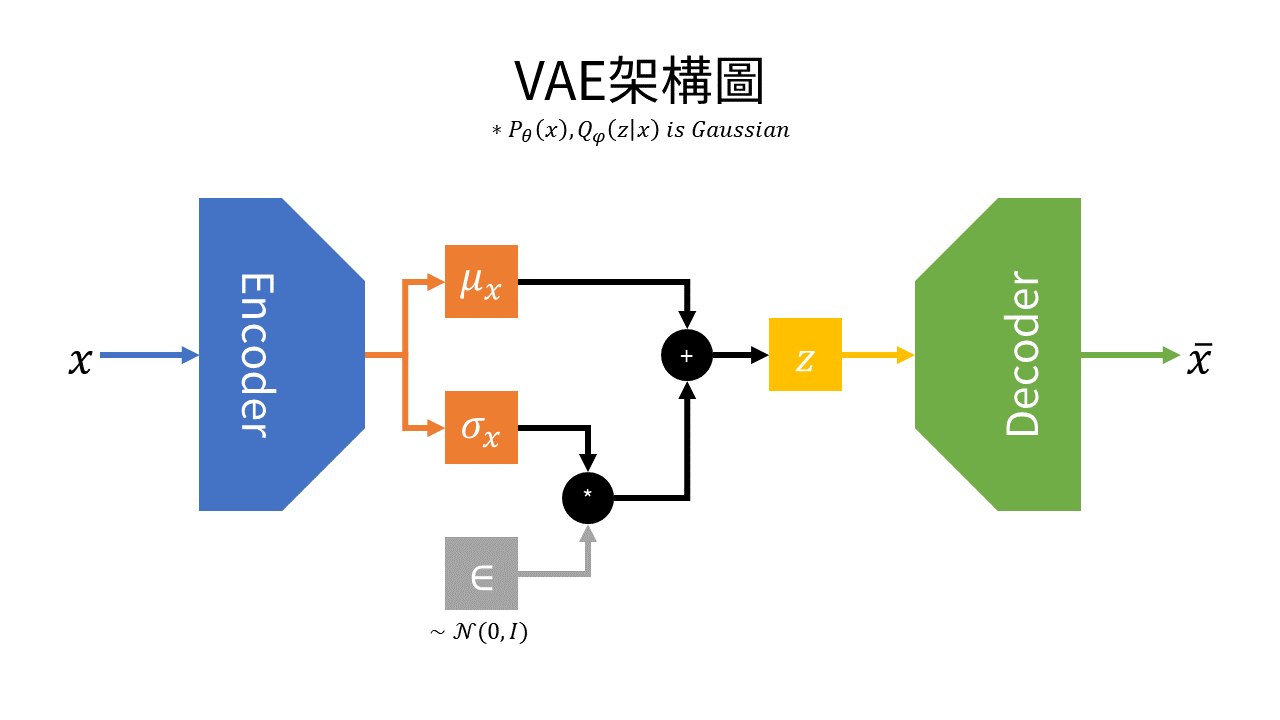 圖1 VAE架構圖
圖1 VAE架構圖一般假設輸入資料分佈Pθ(x)與近似分佈Qϕ(x)皆為高斯分佈,則損失函數LVAE為:
LVAE=MSE+DKL(Pθ(x)∣∣Qϕ(x))≃L1l=1∑LlogPθ(x∣z)+21j=1∑J(1+log(σx2)−μx2−σx2)
補充
1. KL 散度(Kullback-Leibler divergence, KLD)簡介
KL 散度是兩機率分佈P與Q之間的差距,其中P為真實分佈,Q為P的近似分佈。
KL 散度為 非負值 ,如下式:
DKL(P∣∣Q)≥0
雖然可將 KL 散度看作某種距離,但須注意其 不具對稱性 ,如下式:
DKL(P∣∣Q)=DKL(Q∣∣P)
資料來源